Test Theories: TCT And TRI

Tests are used in psychology as measuring instruments. To get a little closer to the concept, just as we use the meter to measure length, we could use a test to measure intelligence, memory, attention… One of the differences between one action and the other would be that the tests are not so easy to measure. build, and not so easy to apply.
Furthermore, just as a single measure does not allow us to talk about the volume of an object, administering a single test does not allow us to diagnose or propose an intervention. Thus, tests are important for the assessment, but they are not decisive.
This is where the psychologist plays the most important role: somehow, he or she needs to use the information he has gained from the test and other sources to shape a coherent assessment that gives way to intervention planning.
In other words, it is in the integration of results from different sources that the professional’s quality is most noticeable. We are talking about a skill that is achieved with knowledge, but also with years of experience.
Brief history of testing theories
The origin of the tests is often cited in tests carried out by Chinese emperors in the years 3000 BC. They were intended to assess the professional competence of the officers who would be at their service. (1)
Current tests have their closest origins in the tests carried out by Galton (1822-1911) in his laboratory. However, it was James Cattell who first used the term mental testing in 1890.
As these early tests were not very predictive of human cognitive ability, researchers such as Binet and Simon (1905) introduced, in their new scale, cognitive tasks to assess aspects such as judgment, understanding and reasoning.
Binet’s scale inaugurated a tradition of individual scales. In addition to cognitive testing, there have been great advances in personality testing.

Why are test theories necessary?
Given all the advances produced, measurement theories (test theories) are being developed that directly affect tests as the instruments they are.
With the concern to generate instruments that measure what we want them to measure and do it with as little error as possible, psychometrics emerges. A psychometry that will require any test or measuring instrument that is valid and reliable.
We must remember that reliability is understood as the stability or consistency of measurements when the measurement process is repeated. In other words, a test will be more reliable the better the results are replicated when measuring two subjects – or the same subject at different times – who have the same measured level.
On the other hand, validity refers to the degree to which empirical evidence and theory support the interpretation of test scores. (two)
Thus, there are two major test theories or approaches when we talk about analyzing and building this type of instrument: the classical test theory (TCT) and the item response theory (IRT).
The classical theory of tests (TCT)
It is the dominant theory in test construction and analysis. The reason: it’s relatively easy to create tests that meet the minimums required by this paradigm. It is also relatively simple to evaluate the test itself regarding the mentioned parameters: reliability and validity.
It has its origins in Spearman’s works at the beginning of the 20th century. Then, in 1968, researchers Lord and Novick undertook a reformulation of that theory and paved the way for the new approach to TRI.
This theory is based on the classic linear model. This model was proposed by Spearman and consists of assuming that the score that a person obtains in a test, which we call an empirical score, and which is usually designated with the letter X, is formed by two components. (two)
On the one hand, we find the subject’s real score on the test (V) and, on the other, the error (e). It is expressed as follows: X = V + e.
Spearman adds three assumptions to this theory:
- First, define the true score (V) as the expected value of the empirical score : this is the score a person would get on a test if they did it an infinite number of times.
- There is no relationship between the number of true scores and the size of errors that affect those scores.
- Finally, measurement errors in one test are unrelated to measurement errors in a different test.
To arrive at this theory, Spearman defined parallel tests as those that measure the same but with different items.
Limitations of the classic approach
The first limitation is that, within this theory, the measures are not invariant in relation to the instrument used. This means that if a psychologist assesses the intelligence of three people with a different test for each, the results will not be comparable. But why does this happen?
The results of the three measuring instruments are not on the same scale: each test has its own scale. In order to be able to compare, for example, the intelligence of X people who have been assessed with different intelligence tests, it is necessary to transform the scores obtained directly from the test into other scales.
The problem with this is that, by turning the scores into scales, we assume that the normative groups on which the scales of the different tests were drawn are comparable – same mean, same standard deviation – which is difficult to guarantee in practice.
(1) Thus, the new IRT approach was a great advance in relation to this fact. TRI will thus ensure that the results obtained using different instruments are on the same scale.
The second limitation of this approach is the absence of invariance of test properties in relation to the people used to estimate it. Thus, in TCT, the important psychometric properties of tests depend on the type of sample used to calculate them. This is a fact that also finds a solution, at least partially, in the IRT approach.

The Item Response Theory (TRI)
Item Response Theory (IRT) was born as a complement to the theory of classical tests. In other words, TCT and TRI could assess the same test, as well as establish a score or relevance for each of the items, which, in turn, could give us a different result for each person.
On the other hand, when pointing out that IRT would give us a much better calibrated instrument, the problem is that this paradigm has a much higher cost and requires the participation of specialized professionals.
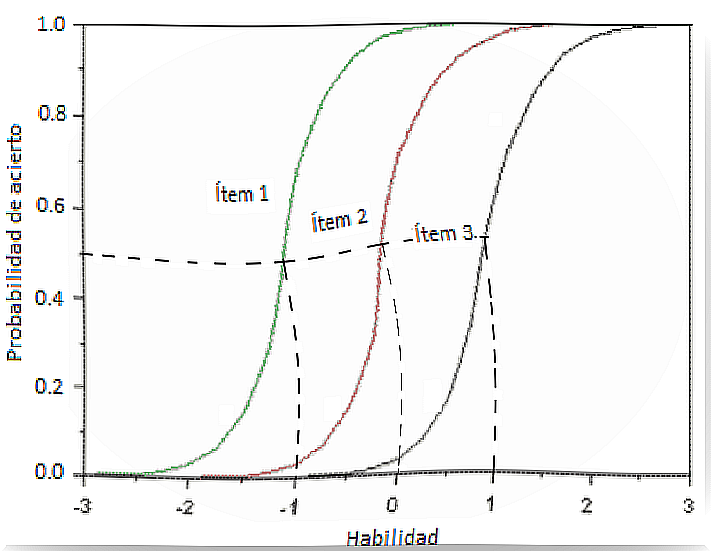
IRT has several assumptions, but perhaps the most important is that any measurement instrument should be aligned with an idea: there is a functional relationship between the values of the variable that measures the items and the probability of getting them right. This function is called the item characteristic curve (CCI). What do we suppose then?
Well, something that from the outside might seem very logical and that TCT doesn’t evaluate. For example, the most difficult items would be those that only the smartest people answer. On the other hand, an item that everyone answers correctly would not be worth it because it would not have the power to discriminate. In other words, it wouldn’t give any information. This is just a small sketch of the revolution proposed by TRI.
To better see the differences between one measurement model and another, we can refer to the table by José Muñiz (2010):
Table 1. Differences between TCT and TRI (Muñiz, 2010)
| Aspects | TCT | TRI |
| Model | Linear | Not linear |
| assumption | Weak (easy to comply with data) | Strong (difficult to comply with data) |
| Measurement invariance | Not | Yes |
| Invariance of test properties | Not | Yes |
| scale of scores | Between 0 and the maximum in the test | Infinite |
| Emphasis | Test | Item |
| Test-item relationship | Not specified | Item characteristic curve |
| Description of items |
Difficulty and Discrimination Indices | Parameters a, b, c |
| Measurement errors | Typical measurement error common for the entire sample | Information functions (varies by level of proficiency) |
| Sample size | May work well with samples of approximately 200 to 500 individuals | More than 500 individuals recommended |
This is how the two test theories relate. Although almost contemporary, it seems clear that IRT is born in response to the limitations or problems that TCT can develop. However, it is clear that research still has a long way to go in this field of psychometry.









